
How LLMs Represent So Many Features
My experience learning about another part of mechanistic interpretability: sparse autoencoders and the study of polysemanticity + superposition

Originally, this blog post was planned for the end of July or beginning of August. Unfortunately, two things happened. Firstly, I drastically underestimated the time it would take me to go through the content for this blog post: parts 1.1, 1.6, and 1.7 of Neel Nanda’s Superposition and Sparse Autoencoders tutorial. Secondly, I had two separate whole-weekend trips, one of which I primarily organized.
There isn’t much of an excuse for the first thing. Before committing to writing about superposition and sparse autoencoders, I could’ve scrolled through the tutorial’s colab notebook and manually added together all the exercise time limits, multiplied it by ~1.5x to account for reading and other things, and gotten a far better estimate. But I didn’t think of that until I was already a good ways through the tutorial, and by then it was too late.
And so at the end of July, instead of writing this post, I found myself barely hanging on in a car swerving along the mountainous roads of California Highway 1.




With that out of the way, let’s talk about Sparse Autoencoders (SAEs)! I do recommend that anyone interested in ML interpretability with a bit of ML background go through the Colab exercises themselves. You can find my own copy of the Colab, with all of my answers, in this blog’s GitHub repo.
Problem Setting
Despite being pervasive, AI is still not well understood. We understand it in the sense that we know what computations (“weights” or “neurons”) are happening in what order (“architecture”). We also know how to modify those weights en masse to get the model to spit out giraffe pics. But when it comes to explaining which parts of the model “know” anything about giraffes, and why it looks a particular way, our understanding becomes more iffy.
Perhaps the most famous architecture is the Transformer—the model powering ChatGPT and all other leading chatbots, among other things. The decoder-only transformer architecture isn’t particularly complicated:

The residual block in the image can also be referred to as a “transformer block.” The two main components within the block are the attention layer (the attention heads in the image), and the MLP.
While this may look straightforward, we don’t actually have a good understanding of the transformer. Mechanistic interpretability is the subfield of AI dedicated to understanding models, including transformers. While the field can be highly theoretical, I think it has exciting applications too. For instance, ROME, the basis of MEMIT, used the fact that attention layers seem to transfer information between transformer blocks, that MLP layers store facts, and that transformer blocks are to some extent interchangeable to inform its flagship fact-editing technique. In broader strokes, more information about underlying model behavior means more potential avenues through which to control said behavior, giving users far greater leverage over their AI.
Predictably, the field is moving very fast. A page I referenced in a previous post, the 200 concrete open problems in mechanistic interpretability, now features an edit stating that many problems are out of date:

In particular, it points to one method that goes unmentioned in the original set of problems: Sparse Autoencoders.
Why Sparse Autoencoders?
To have a better understanding of why sparse autoencoders are interesting, let’s zoom back out to the model. There is empirical evidence that ML models represent more “features,” or important properties of the input1, than the number of dimensions in the model. This property is known as superposition.
In part 1 of the SAE tutorial, we actually demonstrate superposition on a toy model with just two output neurons, by showing that under certain conditions, these neurons fire in 5 distinct directions:
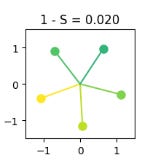
Models representing features in superposition has a number of implications. For one thing, it means that it’s mathematically impossible to exactly reverse engineer which features contributed a certain set of activation values2. It also means that investigating model neurons, such as by observing differences in model output after modifying individual neurons3, is fundamentally limited.
That’s where sparse autoencoders come in. A Sparse Autoencoder (SAE) is a sparse dictionary learning algorithm: an algorithm that tries to decompose all input data into sparse linear combinations of features, where “sparse” means that each feature can only be used in a small fraction of the input data. To figure out superimposed features in a model, the SAE takes internal neuron activations (input data), and tries to decompose them into a far larger number of features.
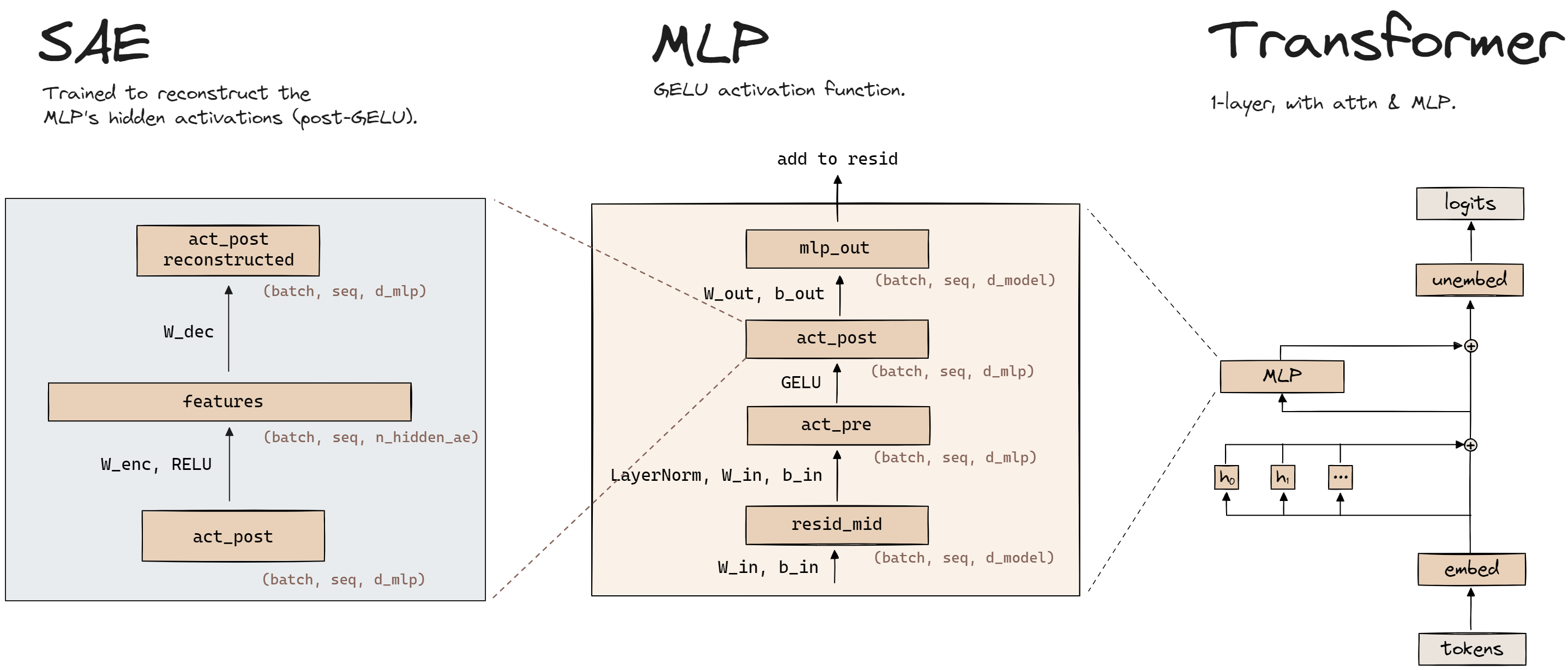
Note that using the SAE isn’t the same as “exactly reverse [engineering] which features contributed a certain set of activation values.” As part of the SAE algorithm, we make assumptions about the sparsity of features, instead of allowing any arbitrary combination of features. It’s this assumption that allows the SAE to make tractable empirical progress, even if theoretically, fully solving the problem is impossible.
In Anthropic’s paper on applying SAEs to transformers, the authors are able to find over tens of thousands of superimposed features in just 512 neurons. They find features that are effectively invisible if you just look at neurons, discover that many of these superimposed features are interpretable (aka make sense to humans), and more.
For the tutorial, I don’t replicate most of those results. However, that isn’t to say the experience isn’t worthwhile, as I’ll explain.
The Tutorial
The Superposition and Sparse Autoencoders tutorial seeks to guide students through the key findings of Anthropic’s paper. The key parts are sections 1.1, 1.6 and 1.7. Section 1.1 walks you through empirically replicating superposition in a tiny model. Section 1.6 formally introduces the SAE, has you implement it, and uses it to try to recover the superimposed features in Section 1.1’s model. Finally, Section 1.7 applies that SAE you implemented to a real transformer architecture, and walks you through some feature exploration.
Overall, the tutorial’s difficulty was just right to slightly challenging for someone at my level: a fairly solid undergraduate background in ML, with a little research and ML engineering experience. With less of this background, the theoretical content may make less sense, which in turn makes you get less out of coding and the tutorial overall. On the other hand, if you’re more experienced than me and have written a lot of model and research code, you might find some exercises to be overly prescriptive and easy.
One thing I noticed while going through the tutorial is that, while I had little difficulty with the concepts, I got tripped up on coding details when implementing these concepts. For example, in section 1.6, we’re asked to implement the AutoEncoder initialization function. The difficulty is marked with a 1/5, but my implementation kept failing. It turns out I wasn’t wrapping my tensors in nn.Parameter (something I had completely forgotten about):
self.W_enc = t.empty(cfg.n_instances, cfg.n_input_ae, cfg.n_hidden_ae)
self.b_enc = t.empty(cfg.n_instances, cfg.n_hidden_ae)
self.b_dec = t.empty(cfg.n_instances, cfg.n_input_ae)
# originally, I didn't have nn.Parameter, so my implementation failed
self.W_enc = nn.Parameter(nn.init.xavier_normal_(self.W_enc))
self.b_enc = nn.Parameter(nn.init.zeros_(self.b_enc))
self.b_dec = nn.Parameter(nn.init.zeros_(self.b_dec))I think part of this is because I haven’t written model code in a long time, even though I’ve written a lot of adjacent code. That being said, these details weren’t too hard to pick up in the process of the tutorial, and by the end I was running into these issues far less.
I personally had a lot of fun going through the tutorial, and found it to be extremely well-written and structured. The authors effectively make up for the fact that this isn’t a classroom setting with near-immediate access to TAs or the professor by providing extensive detail, without taking away from the experience of doing something substantial yourself. Had the contents of the tutorial been translated to, say, a mini IAP course, I would say it’s in the top 5 most well-designed courses I’ve ever taken.
Labor Day
Well, it’s no longer Labor Day. That being said, despite the cooldown of the AI sector, and a number of reports from banks claiming that Generative AI has no path to viability, creator livelihoods are still at risk from AI.
There are several reasons that’s a problem:
Anecdotal evidence indicates that AI production quality is still nowhere close what’s required of real artists
AI still has a fundamental difficulty with producing “rare” outputs4, which would make creating truly novel things impossible
This isn’t an objective fact I could point to, but I firmly believe that end users, especially those who aren’t technical, should be involved in the creation of any tech product associated with their work. Unfortunately, tech companies have by and large failed to do this—more on this in my next blog post.
So if you’re able to give, consider donating to the Concept Artist Association, or commissioning one of their affiliated human artists for art. The CAA is a major organization behind a fair use lawsuit against Midjourney and other big companies that participate in questionable data practices surrounding Gen AI art—any amount helps.
The technical definition of a feature is, paraphrasing Anthropic’s research, “something that a sufficiently large model would dedicate to a single neuron.”
This is essentially linear algebra. If you have N neurons in superposition representing M features in N-dimensional space, where M > N, then there are infinitely many linear combinations of those M features that could have produced the actual output of those N neurons
While manipulating neuron outputs may be fundamentally limited, it still allows us to better understand what the model may be doing. Of course, I might be biased since I did as part of a paper I worked on in 2020 (see: robust feature visualization section)
I once tried to get Midjourney to generate an anime-style girl with blue hair and a pink vest. I didn’t think the model would struggle with that. Unfortunately, it did. Granted, this was a year or so ago.