

Welcome to my first post (let’s conveniently ignore the fact that I missed my own deadline by over a week)! For those who didn’t read my introductory blog post, this substack will be primarily dedicated to AI topics I’m interested in. This includes interpreting and understanding models, as well as the responsible + ethical development of said models. It’ll also include a grab bag of whatever I feel an urge to write about on a more sporadic basis. Without further ado, here’s the post.
Something seems off
If you follow AI news, you’ve probably heard the word before: hallucination. Hallucination, or rather “the machine is making shit up,” is an issue that plaguing just about every public language model, and one whose solution currently eludes even large companies. Not all too long ago, news about a lawyer citing fake cases spewed by ChatGPT went viral. And many folks in tech circles could not forget the infamous case of Google Bard stating a falsehood during its unveiling demonstration.
A similar issue plagues generative visual models such as Midjourney and Stable Diffusion. The fact that these models struggle to depict the correct number of fingers has ascended to meme status among those following ML developments, although the issue seems to be seeing recent improvement. People also notice artifacts that look like butchered signatures across generated images as well, indicating that the models have no understanding of the difference between art and signature, instead simply mimicking what they “see.”
Why is it off?
At their core, machine learning models are just functions trying to approximate a data distribution via a very large number of examples. Following Occam’s Razor, one can then postulate that the errors all boil down to statistical inaccuracies. So, their producing things that sound or look roughly correct but are actually objectively wrong is completely expected.
Based on this postulate, we conjecture that increasing the amount of data would likely improve the approximation, but that alone would never fully erase falsehoods even as the number of examples increases ad infinitum. This is because human data also includes falsehoods, and modeling the underlying data is not equivalent to figuring out the “truth.”
A number of papers have delved into other reasons: poor decoding, an issue in which the model actually learns the language distribution well but uses a bad text generation method, and functional approximation error, in which the model is unable to truly mathematically represent the underlying distribution.
While the reasons are myriad, these learning problems are often visible at the level of the learned distribution itself, before the model is applied to any real-life problem. In particular, models — even newer modern ones — seem to have a tendency of overpredicting the most common values and underpredicting less common ones.
Experiment
In order to see this phenomena for myself1, I decided to evaluate the generations of MosaicML’s MPT-7B base on 100 samples from one component of its validation set. I conducted the evaluation by splitting the first 256 tokens of each validation example in half, and then asking the model to generate a completion for the half. I then computed the distribution of those generated tokens, and compared that to the distribution of the actual tokens (the ground truth). You can find my code in my substack’s repo.
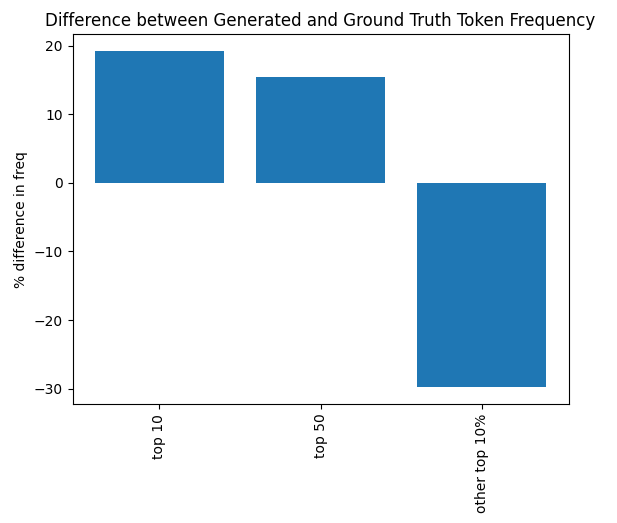
The labels on the bottom of the bar graph indicate how often a token appeared among all possible tokens. My data sample was very small due to compute and time limitations, so as a result the vast majority of tokens allowed were not even generated or present in the ground truth data. The percent in the graph indicates the increase from ground truth to generated, so 20% for top 10 means that the top 10 tokens in the ground truth were 20% more common in the generated data.
In this quick demonstrative experiment, the model still overpredicts common tokens while underpredicting less common tokens from its dataset. However, due to the low amount of data sampled, it is important to take these results with a grain of salt.
The implications
AI generated content is flooding the internet and airwaves, a natural consequence of the explosion of public generation models. Because of this token distribution shift, however, newer trained models may actually have a worse representation of reality, barring new breakthroughs in the field. This is because common things will be overrepresented in AI generated content, shifting the data for the next generation of AI models, ultimately causing models to effectively forget about rare things.
One paper linked earlier puts it aptly: “The Curse of Recursion.” The paper also provides a bleak outlook for “saving” poisoned models trained on a lot of machine outputs, claiming through their experiments that the defects are “irreversible.”
Parting thoughts
From my understanding, the failure of models to understand reality the way humans do has existed for as the models themselves. Yet this has never stopped organizations and individuals from trying to use AI to learn some sort of objective “truth,” and having to mop up the inevitable negative consequences. To a generative AI, truth is merely what it sees the most in its training.
Despite this drawback, been unmoored from truth isn’t strictly negative. It is great for idea generation, such as for TTRPG story design, and even has applications in protein design. What’s important is not necessarily using models less, but rather using them “correctly,” in ways that respect their limitations.
The applications of the technology are not set in stone by a higher order — it is up to us to decide those applications.
If you liked this and want to see more, don’t forget to subscribe!
The authors of “The Curse of Recursion: Training on Generated Data Makes Models Forget” do actually demonstrate this; but don’t directly examine any LLM token distributions. So I decided to try that out myself. This is supposed to be a “quick-and-dirty” experiment that illustrates the point; a formal research project into this subject would require much more resources and time.